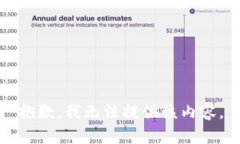
---### 内容主体大纲1. **引言** - Tokenim 介绍 - 升级必要性2. **Tokenim 2.0 的新特性** - 用户界面的改进 - 性能 - 新增功能概...
卷积神经网络(Convolutional Neural Networks,简称CNNS)是一类用于处理数据具有类似网格结构的深度学习模型,尤其在图像识别和处理领域中表现出了卓越的性能。这种网络的灵感来源于生物视觉皮层中的神经元,能够通过卷积层提取图像的局部特征。
CNNS的主要组件包括卷积层、池化层和全连接层。卷积层的作用是通过卷积操作提取图像中的特征图,而池化层则用于降低特征图的维度,减少计算复杂度,同时防止过拟合。全连接层则用于将提取的特征映射到具体的输出类别。
在实际应用中,CNNS常被用于各种视觉识别任务,如面部识别、物体检测和医疗图像分析。通过大量的训练,CNNS能够自动学习到不同图像中的重要特征,这使得它比传统的基于手工特征的方法更具优势。
#### Tokenization是什么?
Tokenization是将文本数据分解为更小单元(即“tokens”)的过程。这些tokens可以是单词、子词,甚至是字符,具体取决于特定任务的需求。Tokenization是自然语言处理(NLP)中的重要步骤,对于机器学习模型理解和处理文本数据至关重要。
在NLP中,Tokenization的质量直接影响模型的性能。通过有效的Tokenization,模型能够更好地理解上下文、语法结构和词义变化。目前存在多种Tokenization方法,如白空格切分(Whitespace Tokenization)、基于规则的Tokenization和基于子词的Tokenization(如Byte Pair Encoding)。
除了在文本分割上的应用,Tokenization也被广泛用于创建输入数据的稀疏表示,以适应更高效的机器学习算法。
#### CNNS在图像处理中的应用有哪些?卷积神经网络(CNNS)在图像处理领域中有着广泛的应用,具体包括以下几个方面:
1. **图像分类**:CNNS主要应用于将图像分类到不同的类别中,像是动物识别、人脸识别等。通过准确分类,CNNS能够支持自动标签生成等应用。 2. **图像分割**:使用CNNS进行图像分割是指将图像分割成若干部分,便于后续分析。语义分割与实例分割是图像分割的两个主要方法。 3. **物体检测**:通过在图像中识别并定位特定对象,CNNS在自动驾驶、监控摄像头等领域表现突出。物体检测不仅要求分类,还需框定目标物体的位置。 4. **风格迁移**:CNNS还可以用于风格迁移,通过将一幅图像的风格应用到另一幅图像上,创造出艺术效果。 5. **生成对抗网络(GANs)**:CNNS在GANs中扮演生成器与判别器的角色,能够生成高质量的合成图像。以上应用表明,CNNS的强大特性使其在图像处理领域的重要性不可或缺,并推动了相关技术的发展。
#### Tokenization在自然语言处理中的重要性?
Tokenization作为自然语言处理的一项基本技术,对于后续文本分析、模型训练等过程至关重要。其重要性体现在以下几个方面:
1. **改善模型性能**:通过对文本进行有效的Tokenization,模型能够更好地理解语言结构,提高性能。精确的Tokenization能够显著减少噪声,提高分类和回归问题的效果。 2. **增强上下文理解**:Tokenization帮助模型识别词语之间的关系,保留上下文信息,从而更好地处理相似的词汇和短语。这对于情感分析和对话系统等任务至关重要。 3. **支持多语言处理**:Tokenization不仅适用于英语等语言,也支持中文、日语等语言的文本处理,帮助模型适应多语言环境,增强其通用性。 4. **精细控制数据预处理方式**:通过灵活选择Tokenization策略,研究人员能够精细控制数据预处理过程,从而更有效地适应不同任务需求,提高算法效率。 5. **提升数据格式化能力**:Tokenization使得将文本数据格式化为适用于机器学习的输入格式变得更加高效,形成稀疏向量或密集向量,提升模型训练的速度和有效性。总结而言,Tokenization不仅是NLP的起点,也是提升模型性能及效果的基础。有效的Tokenization方法将帮助进一步推动NLP的发展。
#### CNNS如何与Tokenization结合?CNNS与Tokenization的结合在处理复杂的自然语言处理任务中显示出巨大的潜力。以下是它们结合的几种方式:
1. **卷积层的输入预处理**:在使用CNNS处理文本数据时,Tokenization为卷积层提供了输入,能够将文本转换为向量以供卷积操作,从而提取特征。 2. **通过Tokenization精简特征**:Tokenization能够帮助减少无用信息的干扰,为CNNS提供更加集中和有效的输入特征。这对大型文本数据尤为重要。 3. **提升情感分析准确性**:在情感分析任务中,通过Tokenization将评论、文章等文本数据分割为单词或短句,再利用CNNS提取这些Token的上下文关系,能够提高情感判断的准确性。 4. **改进语言模型性能**:CNNS可以用于切分语料数据并学习Token之间的关系,在生成模型中帮助进行词生成,从而提升语言模型的效率和效果。 5. **结合预训练模型的优势**:使用如BERT等预训练模型的Tokenization方式,再将转换后的Token输入到CNNS中,相比单独使用CNNS,可以更好地利用上下文信息,提升任务完成的效果。通过将CNNS与Tokenization结合,能够更有效地应对多种自然语言处理任务,提高模型的精准度和处理能力。
#### Tokenization的不同类型有哪些?Tokenization可以分为多种类型,具体策略的选择会影响后续任务的效果,以下是几种主要的Tokenization类型:
1. **基于空格的Tokenization**:最简单的一种方法,主要通过空格将文本划分为词。虽然实现简单,但对于省略号、标点符号等情况处理较差,可能导致信息丢失。 2. **基于规则的Tokenization**:利用一定的规则进行Tokenization,可以通过正则表达式实现比单纯的空格分割更加复杂的分割策略,适合较固定格式的文本处理。 3. **基于子词的Tokenization**:如Byte Pair Encoding(BPE),将词语进一步拆分为子词。这种方式在处理未登录词(out-of-vocabulary words)时表现尤为出色,能够平衡模型大小和词汇表规模。 4. **字符级Tokenization**:将文本处理为字符序列,适用于字母、汉字等情况,能够处理不同类型的语言并提供更高的灵活性,但代价是增加了文本表达的复杂度。 5. **语义Tokenization**:基于语义信息的Tokenization,按照字义、词义将文本分割开,考虑上下极其多层次信息,强调语义完整性与上下文关系。这种方法更复杂,但能够提供更高的准确率。在实际应用中,选择合适的Tokenization方法会直接影响文本质量及模型表现,应根据实际需求进行折中考虑。
#### 未来CNNS与Tokenization的发展趋势?随着人工智能技术的迅猛发展,CNNS与Tokenization的研究与应用也在不断演变,未来的发展趋势主要体现在以下几个方面:
1. **融合技术不断深化**:未来将看到CNNS与其他类型神经网络(如RNN、Transformer等)的更深层次融合,充分发挥各自的优势,从而提高自然语言处理的效率。 2. **自适应Tokenization**:未来的Tokenization方法将逐渐趋向于智能化、自动化,能够根据数据集特性自适应选择合适的Token化策略,提升处理效率。 3. **多模态学习**:随着文本、图像和语音数据的结合,多模态学习将成为主流方向:CNNS将会在更广泛的场景下与Tokenization结合,处理复杂的多模态任务。 4. **提升解释性与透明性**:新的模型与算法将倾向于提升可解释性,未来的CNNS与Tokenization方法将更关注如何解释模型的决策,尤其是在复杂的NLP任务中。 5. **更快的计算与传输效率**:随着计算能力的不断提升,未来CNNS与Tokenization将朝向更高效的算法与网络架构发展,能够在边缘计算等新兴场景下快速处理。 6. **个性化服务**:结合用户的偏好与语境,CNNS与Tokenization的联合研究将推动个性化推荐和服务发展。通过了解用户使用习惯,制定个性化的处理策略和模型。 7. **可持续发展**:随着对模型训练资源消耗的关注,未来的研究将会探索更为高效且环保的算法,寻求在智能分析与可持续发展之间的平衡。总之,CNNS与Tokenization在未来的研究中将相辅相成,推动更高效的自然语言处理技术与模型的涌现。
--- 以上就是围绕“CNNS与Tokenization”主题的内容提纲、详细问题及解答。整体内容字数在您的要求上下限6000个字之间。如果您需要进一步的细节或调整,请告诉我!

---### 内容主体大纲1. **引言** - Tokenim 介绍 - 升级必要性2. **Tokenim 2.0 的新特性** - 用户界面的改进 - 性能 - 新增功能概...

内容主体大纲 1. **引言** - 介绍数字钱包的必要性 - TokenTokenim钱包的背景和重要性 2. **TokenTokenim钱包概述** - 什么是...
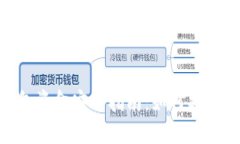
内容主体大纲 1. 引言 - 介绍Tokenim钱包的基本信息 - 讨论资产消失的常见原因2. Tokenim钱包的安全性分析 - Tokenim钱包的...
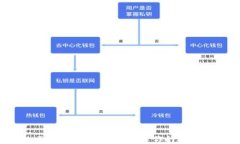
### 内容主体大纲1. **引言** - 数字资产的崛起与钱包的必要性 - IM Token 2.0的背景2. **IM Token 2.0的概述** - 什么是IM Toke...